
虽然 Q* 热度过了,但这篇对于OpenAI Q*的分析文章值得一读:《如何理解关于 OpenAI Q* 的流言 | How to think about the OpenAI Q* rumors》
部分内容摘录:
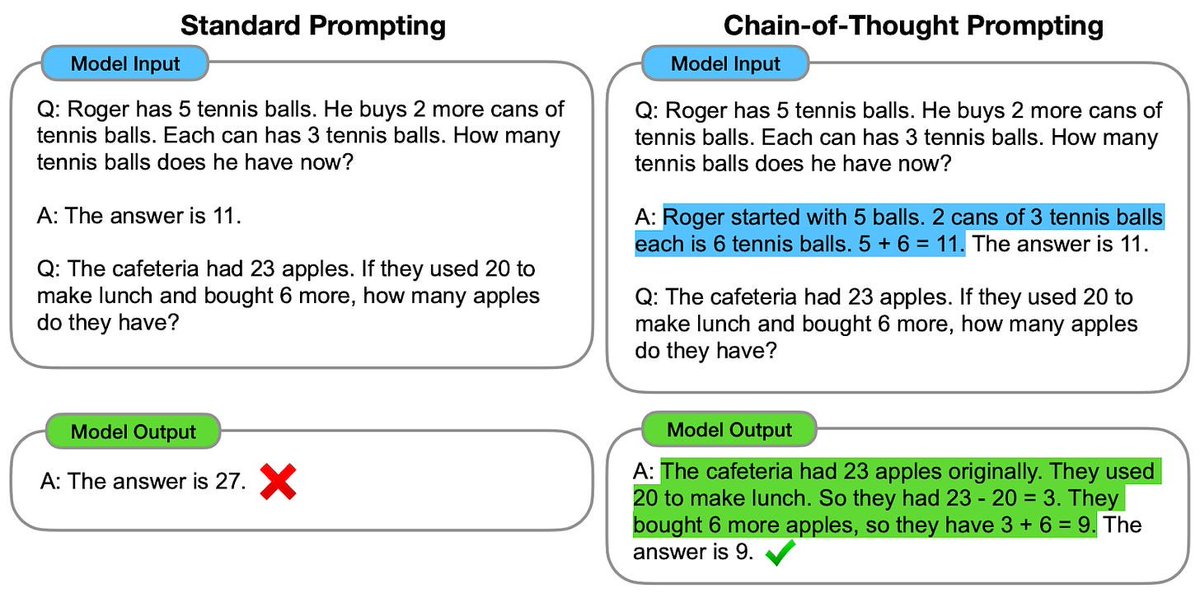
对大语言模型(LLM)来说,数字如“5”和“6”只是普通的 Token,和“the”或“cat”没什么两样。LLM 能学会 5+6=11,是因为在它的训练数据中,这种…
IT技术
(
twitter.com
)
虽然 Q* 热度过了,但这篇对于OpenAI Q*的分析文章值得一读:《如何理解关于 OpenAI Q* 的流言 | How to think about the OpenAI Q* rumors》
部分内容摘录:
对大语言模型(LLM)来说,数字如“5”和“6”只是普通的 Token,和“the”或“cat”没什么两样。LLM 能学会 5+6=11,是因为在它的训练数据中,这种 Token 序列及其变体(比如“5+6=11”)出现了无数次。但这些训练数据很可能不包含像 ((5+6-3-3-1)/2+3+7)/3+4=8 这样的复杂计算例子。因此,当要求语言模型一次性解决这样的计算问题时,它很可能会混淆,从而得出错误的答案。
换个角度来看,大语言模型并没有外部的“草稿空间”来记录中间计算结果,比如 5+6=11。通过链式思考推理(chain-of-thought reasoning),LLM 可以有效地利用自己的输出作为草稿空间。这使得它能将复杂问题分解成若干容易处理的小步骤——每个步骤都极有可能对应训练数据中的某些实例。
...
计算机科学家将其定义为 NP-hard 问题,即不存在一种普遍的线性解决算法。解决这类问题,我们只能尝试一个可能的解决方案,检验其是否有效,若不行则进行回溯。
对于 GPT-4 来说,它可以通过向其上下文窗口增加更多文本来实现这种回溯,但这种方法并不适合大规模应用。更优的方案是赋予 GPT-4“退格键”,使其能删除最后(或最后几个)推理步骤,然后重新尝试。要使这种方法行之有效,系统还需能够追踪已尝试过的组合,以避免重复努力。这样,大语言模型就能探索一个可能性树,其形式如下图所示。
...
Legg 提到的“著名的第 37 步”,是指 AlphaGo 和世界顶级围棋手李世石在2016 年对决中的第二局。当时,大多数围棋专家起初都认为 AlphaGo 的这一步是失误。但最终 AlphaGo 赢得了比赛,事后分析证明这实际上是一个高明的着法。AlphaGo 在这一过程中领悟到了围棋的某些人类棋手未曾触及的奥秘。
AlphaGo 通过模拟成千上万种从当前棋盘状态出发的可能棋局来获得这样的领悟。由于可能的走法序列太多,电脑无法一一检查,AlphaGo 便利用神经网络来使这个过程可控。
其中一个名为策略网络 (policy network) 的网络用于预测哪些走法最有前景,从而值得在模拟对局中尝试。另一个名为价值网络 (value network) 的网络则估算结果棋盘状态对于黑白双方的利弊。AlphaGo 基于这些评估,从而反向确定下一步的最佳走法。
Legg 提出的观点是,一种类似树搜索的方法可能会增强大语言模型(Large Language Model)的推理能力。这种模型不仅仅是预测一个最有可能的 Token,而是在确定答案之前,可能会探索数千种不同的回答。实际上,DeepMind 的思考树(Tree of Thoughts)论文看起来就是向这个方向迈出的第一步。
我们之前看到,OpenAI 尝试通过一个生成器(产生可能的解决方案)和一个验证器(判断这些解决方案是否正确)来解决数学问题。这和 AlphaGo 的设计有明显的相似之处,AlphaGo 有一个策略网络(产生可能的棋步)和一个价值网络(估计这些棋步是否能带来有利的棋盘局面)。
如果把 OpenAI 的生成器和验证器网络与 DeepMind 的思考树(Tree of Thoughts)概念结合起来,我们可能就能得到一个像 AlphaGo 那样运作的语言模型,它可能也会具备 AlphaGo 那样强大的推理能力。
...
原文:https://t.co/jOZr3lA7vv
翻译:https://t.co/XPoRNsU2if
点击图片查看原图

点击图片查看原图

点击图片查看原图
